
Ubikvitinový protein: náhoda, nebo design?
Nyní pracujeme na odborných a jazykových korekturách a na přípravě grafiky.
Link na článek v angličtině: The ubiquitin protein: chance or design?
Autor: Royal Truman
V originále vydáno: The ubiquitin protein: chance or design?, 8. června 2006
Bylo zjištěno, že tři pozice aminokyselin na řetězci jsou charakteristické pro organismy patřící do živočišné, rostlinné a houbové říše. Čtvrtá varianta již byla zaznamenána. Nečekaná identifikace tří nových odlišných tříd UB má důsledky pro evoluční teorii. Vyžaduje, aby společný předek pro všechny rodiny UB byl v podstatě současný se vznikem prvního eukaryota.
Ubikvitin (UB) je klíčový protein, o němž se předpokládá, že je přítomen ve všech buňkách eukaryotního typu. To znamená, že organismy jako kvasinky, rostliny, ryby, savci atd. mají UB. Evoluční teorie to vysvětluje postulátem společného předka. Úzký rozsah variability sekvence aminokyselin, který se vyskytuje v celé přírodě, se však zdá být v rozporu s představou dávného původu a velmi malé změny v důsledku mutací. Vzhledem k velkému množství údajů dostupných ve veřejných databázích jsem se rozhodl zjistit, jak velká rozmanitost v sekvenci aminokyselin existuje a jak by bylo možné tyto údaje interpretovat z hlediska kreacionistů nebo evolucionistů.
Některé třídy proteinů vykazují značnou rozmanitost v sekvencích aminokyselin a příliš se neliší od jiných rodin proteinů. V těchto případech není tak snadné argumentovat, zda je správný kreacionistický nebo evolucionistický pohled. Mohly by se však najít extrémní příklady, které je obtížné vysvětlit evolučně. Takovým případem by byl úzký rozsah přijatelné variability v širokém spektru taxonů a nepřítomnost jiných rodin proteinů s podobnými sekvencemi.
Miliardy let mutací v geneticky oddělených liniích by jistě přinesly mnoho změn. Pokud se najde velmi malá rozmanitost, pak je jistě funkčních jen málo alternativ. A pokud prakticky žádná není funkční, bylo by mimořádně nepravděpodobné, že by evoluční východisko, na které by působil přírodní výběr, bylo nalezeno náhodnými mutacemi. Nepřítomnost podobných tříd proteinů by naznačovala neexistenci mezistupňů, které by spojovaly neužitečné geny s geny kódujícími vysoce specializované proteiny.
Ubikvitin je zajímavým kandidátem na zkoumání, protože standardní univerzitní učebnice tvrdí, že jeho sekvence je u mnoha druhů organismů velmi málo variabilní. Přesné množství zatím nebylo v literatuře uvedeno, a to s využitím všech údajů, které jsou nyní k dispozici. Zdá se, že nebyla zaznamenána ani žádná snaha o identifikaci kandidátních evolučně předpotopních tříd proteinů.
Existuje ještě poslední problém, kterým se v případě ubikvitinu budeme zabývat později. Existují příklady vysoce omezených proteinů, u nichž je současně vyžadováno velké množství jiných proteinů, než mohou nabídnout nějakou selektivní výhodu? Existence takových molekulárních strojů by naznačovala „neredukovatelnou složitost“: přírodní výběr by mohl být účinný pouze tehdy, když je vše na svém místě, ale jsou zapotřebí i velmi nepravděpodobné komponenty.
Soubor dat sekvencí
Vyhledávání blast-p1 na základě známé sekvence ubikvitinu identifikovalo asi 860 podobných sekvencí, které byly staženy do počítače.
Než bylo možné data podrobněji prozkoumat, bylo nutné provést určité předběžné zpracování. Po vyloučení byl vytvořen soubor:
- Polypeptidových sekvencí připojených k ubikvitinovému proteinu. V této době mě zajímala funkčnost a variabilita volných UB
- Sekvence získané z virů. Nemohl jsem určit zdrojový organismus, ze kterého byly získány, a zda jsou funkční.
- Exotické sekvence nalezené u jednobuněčných parazitů. Nemohl jsem si být jistý, zda tyto UB fungují normálně, vzhledem k tomu, že mRNA UB je pravděpodobně dostupná i prostřednictvím hostitele
- Duplicitní sekvence ze stejných organismů. (Často se UB vyskytují v mnoha kopiích na stejném genomu).
- Sekvence, u nichž nebyl organismus anotován ve zdrojové databázi.
Vyčištění datové sady bylo provedeno ručně, aby se zajistilo, že nedojde ke ztrátě dat. Například pokud byly nalezeny identické sekvence pro stejný organismus, nahlášené z různých laboratoří, byla v datovém souboru ponechána první z nich. V případě, že bylo sloučeno velké množství UB, byla ponechána první z nich. Sekvence z virů byly odstraněny a uloženy do samostatného souboru.
Skripty naprogramované pomocí ActiveState perl2 potvrdily integritu snahy. Skripty, jako jsou uvedeny v příloze A3 a v příloze B4, mohou při těchto druzích činností ušetřit přibližně týden úsilí. Nové údaje přidané do veřejných databází1 později mohou vyžadovat vytvoření budoucích datových souborů a takové skripty mohou ušetřit mnoho úsilí.
Zarovnání sekvencí
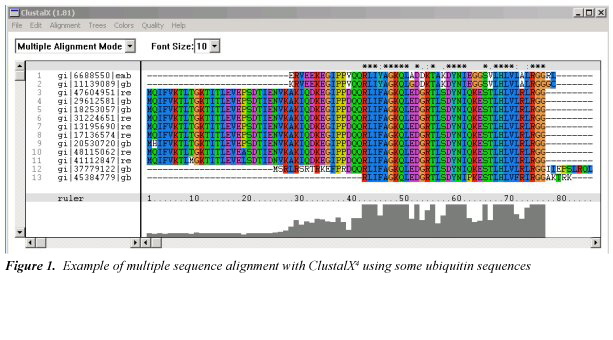
Tabulka 1. Zkratky aminokyselin a chemické struktury. (Kliknutím na obrázek zobrazíte větší obrázek)
Sekvence v souboru dat byly zkoumány po optimálním zarovnání zbytků pomocí nástroje ClustalX verze 1.8.1 utility 4 (obr. 15). Konečná data jsou rovněž k dispozici online6 a skládají se z dat ze 158 různých organismů. Význam jednopísmenných kódů aminokyselin viz tabulka 1. Pro všechny ubikvitiny lze zjistit jedinečné vzory, jako jsou terminální zbytky RGG (kód viz tabulka 1), které lze použít jako parametry v perlovém skriptu (příloha A)3 k extrakci a uspořádání sekvencí. V tabulce 2 (dostupné online7) je uveden počet alternativních aminokyselin nalezených na každé ze 76 pozic zbytků ubikvitinu na základě tabulky (dostupné online8) a tabulka 3 dokumentuje zbytky, u nichž byla zjištěna určitá variabilita. Ve 46 pozicích byla nalezena naprosto stejná aminokyselina, což znamená, že přibližně 60 % UB zřejmě nesnáší žádné mutace, a v dalších 17 pozicích byla příležitostně nalezena jedna alternativní aminokyselina (tab. 4). Téměř ve všech posledně jmenovaných případech byla tato výjimka nalezena pouze u jediného organismu a u některých z nich může jít jednoduše o nesprávně uvedené údaje.
Analýza pravděpodobnosti
Než mohl přírodní výběr začít s jemným laděním UB, musí být k dispozici protein s vhodnou sekvencí zajišťující minimální funkčnost. Nový gen musí kódovat polypeptid. Existuje (20)n alternativních polypeptidových sekvencí, kde n je délka řetězce. Jaká je pravděpodobnost, že náhodný polypeptidový řetězec o délce 76 aminokyselin může poskytnout evoluční východisko?
Výpočty teorie informace
Výpočty pravděpodobnosti tohoto druhu založené na teorii informace byly diskutovány již dříve.9 Tato metoda vylučuje „sekvence s nízkou pravděpodobností“, jako jsou řetězce, které se skládají z mnoha aminokyselin, jež jsou kódovány pouze jediným kodonem. Mezi náhodnými řetězci DNA jsem již dříve9 tvrdil, že takové sekvence jsou extrémně nepravděpodobné a teorie informace takové statistické faktory zohledňuje.
Metoda předpokládá, že přítomnost určité aminokyseliny na dané pozici zbytku nemění pravděpodobnost přítomnosti jiných na jiných místech. Je známo, že to není správné. Různé aminokyseliny se mohou vyskytovat v různých funkčních UB na různých pozicích zbytků. To neznamená, že by všechny tyto mutace byly přijatelné, pokud jsou přítomny současně ve stejné UB. Tato chybná extrapolace by při použití údajů v tabulce 3 na základě skutečně hlášených 55 alternativ naznačovala, že existuje 16 796 1600 přijatelných alternativ10, ale při nejvelkorysejších předpokladech by bylo odůvodněno nejvýše 15 820 očekávaných alternativ.10 Podíl odhadovaný jako funkční podle teorie informace, při zanedbání vlivu závislosti na kontextu, je tedy příliš vysoký. To však kompenzuje skutečnost, že v mém souboru údajů o ubikvitinu nebyly identifikovány všechny myslitelné přijatelné mutace.
Výpočty uvedené v dodatku 1 naznačují, že podíl přibližně 4X10-83 polypeptidů o délce 76 zbytků by v živých organismech vytvořil funkční UB.
Tabulka 3. Ubiquitinové sekvence s určitou variabilitou na základě online údajů. (Kliknutím na obrázek zobrazíte větší verzi)
Tabulka 4. Pozice aminokyselinových zbytků na ubikvitinu nevykazující variabilitu nebo maximálně jednu alternativní aminokyselinu pouze u jednoho organismu. Založeno na ref.8. (Kliknutím na obrázek zobrazíte větší verzi)
Různé rodiny ubikvitinu
Zkoumání sekvencí v místech, kde se vyskytuje variabilita, ukazuje, že ve skutečnosti existují různé rodiny UB, seskupené podle živočišné, rostlinné a houbové říše. Diagnostické jsou zejména pozice reziduí 19, 24 a 57 a v menší míře také pozice 16 a 28.
Vzor PES u živočichů
Aminokyselinový vzorec „PES“ uvedený v tabulce 5 platí pro savce, ryby, hmyz, obojživelníky, mnohé prvoky atd. Z této tabulky vyplývá, že sekvence UB pro člověka a ústřice jsou identické.11 UB z prvoků, jako jsou Leishmania tarentolae a Leishmania major, jsou navzájem identické a liší se od lidské UB pouze ve 2 zbytcích.12 Pro mikroorganismy není k dispozici mnoho sekvencí UB a ty, které byly zkoumány, jsou obvykle patogeny lékařského zájmu.
Vzorec PES je natolik konzistentní, že byla rychle zaznamenána výjimka v případě dvou červů.13 Další šetření a korespondence s hlavním autorem prací objasnily, že se jedná o parazitické červy, kteří se živí rostlinami. Vzor UB, který mají, je skutečně charakteristický pro rostliny a je spojen s polypeptidy, které červi vstřikují do hostitelské rostliny, aby modifikovali její vývojové chování. Pravděpodobně tito červi mají také varianty UB s očekávaným vzorem PES, jak se vyskytují u jiných červů (viz online databáze, (ref. 5).
Tabulka 5. Výrazný vzor PES EA a menší AES EA pro živočišné organismy. (Na základě aminokyselin nalezených v pozicích reziduí 19, 24, 57, 16, 28). Viz ref. 5. (Kliknutím na obrázek zobrazíte jeho větší verzi).
Menší vzor AES
Několik organismů mělo na pozici 19 místo P (prolin) A (alanin): někteří červi, včely, jeden šváb, tři řasnatí prvoci a jedna améba. Je třeba ověřit možnost chyb v záznamu, zejména pokud je k dispozici pouze jedna sekvence. V případě některých červů a včel potvrzuje přítomnost této alternativní aminokyseliny více zpráv. Pokud měly původní vytvořené organismy vzor PES, mohla jediná mutace z kteréhokoli ze čtyř kodonů pro prolin (C CU, C CC, C CA, C CG) nyní kódovat alanin (G CU, G CC, G CA, G CG).
Tabulka 6. Charakteristický vzor SDA EA pro organismy podobné rostlinám. (Na základě aminokyselin nalezených v pozicích zbytků 19, 24, 57, 16, 28). Viz ref. 5. (Kliknutím na obrázek zobrazíte jeho větší verzi).
Vzor SDA u rostlin
Vzor „SDA“ uvedený v tabulce 6 pokrývá širokou škálu rostlin.
Vzor SDA pro houby
Vzor „SDS“ uvedený v tabulce 7 charakterizuje houby (které zahrnují kvasinky). Nedostatek variability v rámci velmi odlišných hub je dramatický. Například ubiquitiny Magnaporthe grisea (houba způsobující výbuch rýže) a Tuber borchii (jedlý lanýž / houba) jsou 100% identické14.
Různé vzory
Sekvence UB některých organismů nespadají do žádné z dosud zobrazených kategorií (tabulka 8). U jedné červené řasy byl zjištěn živočišný vzor PES. Možná byla kontaminována například UB z korálů. Pro tento organismus byla nalezena pouze jedna sekvence. Vzor „SEA“ byl nalezen pro zelené řasy, klouzavé bičíkovce a amébu. Rostlinný vzor SDA EA je podobný vzoru SEA, zejména když uvážíme, že aminokyseliny D (kyselina asparagová) a E (kyselina glutamová) jsou si velmi podobné. Ačkoli rostliny vždy vykazovaly EA v pozicích reziduí 16 a 28 (tabulka 6), větší variabilita byla zjištěna u několika výjimečných organismů uvedených v tabulce 8. Je třeba doplnit sekvence, aby bylo možné určit, zda existují další vzorce k těm, které byly identifikovány pro živočichy, rostliny a houby.
Další kategorie ubikvitinu
Jedna nebo dvě aminokyseliny oddělují řetězce jinak souvislých UB u příslušníků protistních linií Cercozoa a Foraminifera (tabulka 9). Protože genová exprese začíná methioninem (M), znamená to, že protein bude mít přidanou jednu nebo dvě aminokyseliny navíc. To je velmi zajímavé, protože koncová glycinová (G76) karboxylová (COOH) skupina hraje rozhodující roli: je přesně upravena pomocí několika enzymů k označení cílového proteinu. Ta vytváří isopeptidovou vazbu s ε-aminoskupinou lysinu. Aminokyseliny následující za G76 by však konjugaci vazbou na tuto klíčovou karboxylovou skupinu zabránily. Je velmi pravděpodobné, že speciální enzymy, které se u jiných organismů nevyskytují, odstraňují tyto zbytky navíc.
Některé z příkladů v tabulce 9 ukazují dipeptid (tj. aminokyseliny MS) předcházející obvyklému M používanému k iniciaci genové exprese. Buď je také vyříznut, nebo je funkční i delší varianta ubikvitinu. Autoři15 považovali tyto znaky UB za dostatečně významné pro tvrzení o blízké evoluční příbuznosti mezi Cercozoa a Foraminifera, ačkoli analýza četných genových sekvencí vytvořila beznadějně protichůdné fylogenetické stromy. Důkazy podporují návrh, že existují nejméně čtyři izolované rodiny UB proteinů. Z tabulky 9 lze vypozorovat, že většinu organismů bychom podle jejich morfologie zařadili k rostlinám a obvykle vykazují vzor SEA.
Diskuse
Evoluční pravděpodobnosti
Musíme zjistit, zda šance na získání funkčního UB z náhodných 76 aminokyselinových polypeptidových řetězců, 4X10-83, na které může působit přírodní výběr, může být splněna přírodními procesy. Alternativní model, v němž UB mohl vzniknout z již existujícího genu, bude zkoumán v jiném článku. Ve dvou nezávislých pracích9,16 byl uveden přibližně stejný odhad maximálního počtu organismů, které mohly žít na Zemi během 4 tisíc milionů let: 1046. Odhady mutačních rychlostí se pohybují mezi 10-7 a 10-12 na nukleotid17-21 podle jednotlivých organismů. U malých genomů podobných bakteriím to znamená, že většina těchto organismů neměla mezi většinou generací žádné mutace. Je zřejmé, že pravděpodobnost vzniku pouze jednoho genu UB (plus nezbytného de-ubikvitinačního enzymu potřebného k jeho uvolnění od zbytku polypeptidu) náhodnými mutacemi je nekonečně malá. Mnohem větší průměrná míra mutací by vedla k chybové katastrofě, protože škodlivé chyby by se hromadily u všech členů populace.
Nedávno byly popsány metabolické náklady na expresi duplikovaného genu v kvasinkách22 a autor potvrdil, že výsledkem by byl záporný selekční koeficient. Rychle se množící malé organismy, které exprimují geny bez biologické hodnoty, by byly selektivně znevýhodněny a velikost linií by se zefektivnila již po několika letech. Výsledná absence kandidátního genetického stavebního materiálu u takových domnělých prastarých, primitivních organismů, která by umožnila generování nových genů, vylučuje možnost generování nových, komplexních biologických funkcí prostřednictvím evolučních mechanismů.
Kromě toho by nekódující sekvence nezbytné k expresi bezcenných genů byly rychle deaktivovány náhodnými mutacemi, takže i kdyby mutační náhodou vznikla užitečná sekvence DNA, protein by se nevytvořil.
Tyto druhy pravděpodobnostních úvah představují pro evoluční teorii vážné problémy s věrohodností na třech místech:
- Vznik primitivního genetického systému příbuzného těm současným (založeného na 64 kodonech, 20 aminokyselinách a instrukci „stop“) by vyžadoval desítky nepříbuzných proteinů ab initio.
- Zvýšení biologické funkčnosti, které by vysvětlilo to, co pozorujeme dnes, vyžaduje vznik tisíců nových druhů proteinů/génů.
- Celkový počet evolučních pokusů, vycházející z celkového počtu cca 1046 organismů, musí pokrýt všechny destruktivní a neutrální mutace v historii Země; a stále zbývá dostatek pokusů k iniciaci a následnému vyladění tisíců užitečných nových proteinů darwinovskými mechanismy.
Je zřejmé, že metodou pokus-omyl s využitím všech dostupných organismů, které kdy mohly žít na Zemi podle evolucionistického rámce, nelze očekávat vznik jediného minimálně funkčního genu UB. Domnívám se, že argument (iii) dosud nebyl v literatuře rozpracován, a hodlám jej vysvětlit později. Kreacionisté a agnostici argumentovali tím, že dostupný čas omezuje počet evolučních pokusů. Omezení v bodě (iii) tvrdí, že celkový počet mutantů, kteří žili, nestačí k vysvětlení součtu všech genů, o nichž je známo, že v současnosti existují.23
Pravděpodobnosti v malých skocích
Když jsem tvrdil, že pravděpodobnost, že někdy vznikne počáteční gen kódující UB, je v podstatě nulová, implicitně jsem předpokládal, že výchozím bodem byla náhodná sekvence.
Obrázek 2. Varianty bílkovin mohou nabízet most k vzájemné evoluci.
Současné evoluční myšlení předpokládá, že nové funkce obvykle vznikly v důsledku duplikace genů, po níž následovala následná divergence prostřednictvím mutací. Předpokládejme, že v genomu byly nalezeny další geny kódující proteiny podobné ubikvitinu. To je koncepčně znázorněno na obr. 2. Klíčovou myšlenkou je, že některé mutace dvou genů mohou být mnohem podobnější než typické nebo konsenzuální sekvence. Několik šťastných mutací by mohlo poskytnout evoluční výchozí bod mnohem snadněji, než kdyby se vycházelo z náhodné sekvence. Nemohla by se statistická náročnost výrazně snížit?
Věrohodnost tohoto konceptu by bylo třeba zkoumat případ od případu. Musí být splněno několik podmínek.
- Duplikovaný gen nesmí zasahovat do exprese jiných genů.
- Rozdílné proteiny a mRNA se nesmí vzájemně rušit. Vzhledem k podobnosti sekvencí je interference velmi pravděpodobná.
- Pokud má dojít k pozitivní selekci, musí být již přítomny všechny ostatní složky nové funkce.
- Nová linie musí přežít genetický drift a zmíněnou selekční nevýhodu.
Aby vznikl původní ubikvitin, jak je znázorněno na obr. 2, musel ve skutečnosti existovat jiný podobný gen. Jedinými kandidáty dostupnými v existujících sekvenčních databázích jsou tzv. ubikvitinu podobné proteiny (UBL). V navazujícím článku budu tvrdit, že vyvinout ubikvitin z řetězce předchozích UBL je ve skutečnosti obtížnější než z náhodného úseku DNA.
Velmi omezená variabilita mezi známými sekvencemi ubikvitinu (tab. 4) znamená, že shluk alternativ v blízkosti pravděpodobně téměř optimální konsensuální sekvence (obr. 2) je velmi úzký. To naznačuje, že homology UB by musely nejprve vzniknout duplikací genů a poté by muselo být zmutováno mnoho aminokyselin, čímž by vznikly nefunkční proteiny UB, než by se mohl vyvinout minimálně užitečný nový gen. Požadavek, aby bylo za tímto účelem modifikováno více než pět aminokyselin, je statisticky nereálný.24 Sekvence několika druhů UBL vykazují velmi omezenou variabilitu napříč organismy a jsou příliš vzdálené od sekvencí UB na to, aby pocházely od společného předka.25
Tabulka 9. Polyubikvitinové sekvence oddělené jednou nebo dvěma aminokyselinami. (Kliknutím na obrázek zobrazíte jeho větší verzi)
Biochemie ubikvitinu
Dosud jsem se soustředil pouze na nepravděpodobnost výroby proteinu UB. Samotný UB je však biologicky bezcenný, stejně jako prakticky všechny ostatní proteiny. Je užitečný pouze tehdy, je-li začleněn do procesu s dalšími biochemickými látkami. Aby měl UB selektivní hodnotu, musíme se podívat na celý obraz.
UB o 76 reziduích je zřídkakdy kódován pouze jedním genem,26,27 ale je součástí větších proteinů, jak je znázorněno na stažených sekvencích ve standardním formátu Fasta (obr. 3). V případě genu UB14 u kvasinek je řada UB připojena k sobě.26 V přírodě je k extrakci části UB zapotřebí speciální de-ubikvitinační enzym26,28
Obrázek 3. Příklady sekvencí ubikvitinových proteinů z vyhledávání Blast.
Substrát, který má být degradován pomocí UB, musí být nejprve identifikován a poté se UB specificky naváže na jednu z lysinových aminokyselin. Slovy jednoho recenzenta,
„Ubikvitin (Ub) je konzervovaný protein o 76 aminokyselinách, který se posttranslačně připojuje k substrátovým proteinům. K této konjugaci dochází prostřednictvím izopeptidové vazby mezi C-koncovým karboxylátem Ub a epsilon-NH2 postranního řetězce lysinu v cílovém proteinu. Konjugace se dosahuje postupným působením aktivačního enzymu E1, konjugačních enzymů E2 a ligáz E3. Odstranění Ub ze substrátů provádějí deubikvitinační enzymy.“29
Zkratky E1, E2 a E3 se v literatuře o UB používají běžně a v jednom organismu existuje mnoho variant, z nichž každá má speciální funkce. Jedná se o velmi složité enzymy a jsou mnohem větší než UB. Části složeného UB musí interagovat přesně ve třech rozměrech se třemi třídami enzymů. Celé schéma je užitečné pouze tehdy, když je pečlivě regulováno. Nerozlišující ničení proteinů, které obsahují aminokyselinu lysin, by buňku rychle zničilo.
UB se podílí na velkém množství buněčných procesů. Regulace buněčného cyklu, řízení růstu, vývoje a reakce na stres vyžadují odbourávání různých regulačních proteinů. Toho se dosahuje navázáním UB za pomoci tří tříd zmíněných enzymů na tyto substráty.30 Proteiny navázané na UB jsou tak cíleně odbourávány a následně degradovány ve složitém stroji zvaném proteasom.30 Ubikvitinace se zaměřuje také na proteiny na povrchu buněk, aby je pomohla pozřít k následné degradaci v lysozomech.31
Proteasom se skládá ze dvou podkomplexů: 20S jádrové částice (CP), která vykonává katalytickou činnost, a 19S regulační částice (RP). 20S CP je soudkovitá struktura složená ze čtyř na sebe naskládaných prstenců, dvou identických vnějších α-prstenců a dvou identických vnitřních β-prstenců. Eukaryotické α- a β-kruhy se skládají každý ze sedmi různých podjednotek.26
Tento přehled zahrnuje pouze některé signalizační funkce, kterých se UB účastní, a ukazuje, že postulovat jeho původ evolučními procesy by vyžadovalo také zvážit, odkud se vzaly všechny ostatní složky, s nimiž se používá, a v jakém pořadí.
Obrázky 4-6. Složená struktura ubikvitinu.
4. Zpřesněno na 1,8 Å, souřadnice z databáze Protein Data Base www.rcsb.org/pdb, položka 1UBQ.pdb. Zobrazeno pomocí prohlížeče proteinů Swiss Prot. 5. Zpřesněno na 1,8 Å, souřadnice z databáze Protein Data Basewww.rcsb.org/pdb, položka 1UBQ.pdb. Zobrazeno pomocí prohlížeče proteinů RasTop. Zvýrazněná struktura páteře. 6. Jiný pohled založený na stejných datech jako na obrázku 4. Jsou zobrazeny zbytky PES a umístění lyzinů. Zobrazeno pomocí prohlížeče proteinů Swiss Prot.
Interpretace údajů o ubikvitinu
Všechny vědecké teorie podléhají revizi, i když se tomu často vehementně brání.32 Nesmíme přehlížet, že chyby v uváděných sekvencích jsou v databázích proteinů a genů bohužel realitou. V mnoha případech jsou data k dispozici pouze z jediného zdroje. Většina organismů má více kopií UB a jedna mutovaná verze nemusí být funkční. UB z parazitů, které mohou do značné míry záviset na genetické výbavě svého hostitele, nemusí u volně žijících organismů fungovat. Bylo zjištěno, že viry někdy obsahují fúzované proteiny připomínající UB. Protože chyběl zbytek enzymů potřebných k označení substrátů a k vytvoření proteazomu, není jasné, zda tyto sekvence skutečně plní nějakou funkci. UB nalezené ve virech byly z této studie vyloučeny.
Při zkoumání skládané struktury UB (obr. 4) jsou patrné některé konstrukční prvky. Výrazný koncový triplet aminokyselin (-RGG) je vystaven na vnějším povrchu proteinu. Tři aminy R (arginin) činí tento zbytek silně hydrofilním. A postranní řetězec G (glycin) je nejmenší možný u aminokyselin, jednoduchý vodík. Kombinovaný účinek spočívá v tom, že koncová skupina COOH, která se podílí na izopeptidové vazbě, je ve vodném prostředí buňky vystavena bez překážek a vzdálena od hydrofobního jádra proteinu (obr. 5). NH2 Lys-48, který se podílí na vícenásobných ubikvitinačních vazbách, je přístupný skupině COOH. M-1 (methionin) je chráněn centrálním hydrofobním jádrem.
Na vzor PES v polohách 19-24-57 se lze podívat (obr. 6) z jiného úhlu pohledu. Ukazuje se, že prolin-19 a serin-57 jsou při skládání UB poměrně blízko u sebe. Možná oba interagují s jedním z enzymů. Prolin je mezi aminokyselinami výjimečný tím, že peptidové vazby vytvářejí v páteři proteinu ostrý lom (protože na amid nezůstává navázán žádný volný vodík). Je možné, že enzym E1 nebo E2 je uzpůsoben tak, aby vyhovoval této vlastnosti většiny živočichů, ale ne jiných druhů organismů.
Je pozoruhodné, že velmi malé rozdíly, které odhalují diagnostické vzorce živočichů, rostlin a hub, mohou být tak důležité. Příslušné enzymy jsou pravděpodobně velmi přesně upraveny tak, aby odpovídaly.
Evoluční interpretace by mohla být taková, že jakmile bylo dosaženo téměř dokonalosti, přírodní výběr omezuje množství variability, které bude následovat. Pokud jsou však rozdíly v selektivitě mezi téměř dokonalou a blízkou variantou skutečně tak dramaticky odlišné, jak by předchozí organismy přežily bez UB?
Jednou z kreacionistických interpretací by bylo, že Bůh navrhl alternativní varianty UB a s nimi spojené enzymy pro různé taxony. Tím by se upravilo, jak rychle jsou různé proteiny zaměřeny na degradaci („pravidla Nend“), optimálně pro potřeby těchto druhů organismů. Mutace v průběhu času by upravily několik méně kritických částí UB.
Různé lyziny (K) na UB slouží různým účelům. Je pozoruhodné, že koncová karboxylová skupina UB dokáže s pomocí různých enzymů rozlišovat mezi sedmi přítomnými zbytky K a vytvářet poly-ubikvitinové řetězce, přičemž k degradaci jiných proteinů využívá především ten na pozici 48, ale také ten na pozici 29. V případě, že se jedná o poly-ubikvitinový řetězec, je možné, že se jedná o poly-ubikvitinový řetězec. Vazba s K63 slouží jako signál nezávislý na proteolýze pro několik procesů. Za zmínku stojí i to, že NH2 dalších aminů postranních řetězců (asparagin, glutamin a arginin) jiných proteinů jsou enzymy rozpoznávány jako nesprávné cíle. Navíc jediná aminokyselina v poloze 57 odlišuje rostliny od hub. Postranní řetězec serinu (S) hub má chemickou funkční skupinu H2C-OH, která je polární a může vytvářet slabé H-vazby, ale přesto je velikostí velmi blízká postrannímu řetězci alaninu (A) rostlin, CH3. To znamená, že varianty enzymů jsou přesně vyladěny tak, aby mohly interagovat na tak malé rozdíly.
Nahrazení prolinu alaninem, jak se vyskytuje u včel, jednoho švába a některých červů, vede k malému, ale pozorovatelnému rozdílu v části složeného UB.
Nejstarší fosilie švába je údajně stará asi 300 milionů let a nejstarší včely 80 milionů let. Nejlepší evolucionistický výklad by zahrnoval nezávislé a náhodné mutace, a nikoli společného předka švábů, včel a některých červů.
Klasický model YEC předpovídá vážné celosvětové oslabení populací švábů a včel způsobené turbulentními podmínkami během a po všeobecné potopě. Toto období mohlo trvat stovky let.33 Několik zakladatelů, kteří měli minoritní vzor AES, mohlo potopu přežít a jejich linie přežily díky genetickému driftu v malých populacích. Jako alternativní vysvětlení se na základě výsledků projektu RATE34 nejnověji uvažuje o tom, že potopu provázelo krátké období vysoké radioaktivity, které mohlo způsobit velké množství mutací v celé biosféře. Během této doby mohlo dojít k P → A. Některé z nich se mohly snadno rychle fixovat ve velmi malých efektivních populacích.
Včely jsou v mnoha ohledech neobvyklé, například jedinečným způsobem, kterým se určuje pohlaví.35 Krátce po Potopě, v níž by existovalo jen málo včelstev, se v populaci mohla fixovat jedna z těch, které nesly mutantní UB. Přímé křížení mezi přímými potomky téže královny a extrémně malý počet reprodukčních členů by usnadnily fixaci mutace.
Všimněte si, že červi jsou hermafroditi, což usnadňuje fixaci mutací.
Aminokyseliny navíc na kritických místech přítomné u Cercozoa vylučují evoluční scénář: živočichové → Cercozoa → rostliny (P E S → S E A → S D A ).
V současné době nám chybí rozsáhlý soubor dat s mnohem širší škálou organismů, zejména těch blízce příbuzných (jako jsou různé druhy švábů). Chybí nám také široká škála sekvencí od stejného druhu, abychom zjistili, jak velká je variabilita od druhově specifické konsenzuální sekvence. Dokud nebude k dispozici více údajů, nemůžeme si být jisti, že zvířecí vzor AES není záměrně navrženým rysem.
UB a evoluční časová škála
Obrázek 7. Diagnostický ubikvitinový vzor pro živočišné, houbové a rostlinné životní formy nevykazuje v podstatě žádnou variabilitu v rámci těchto tří linií. Neexistuje žádný důkaz, že ubikvitin vznikl z jediné genové sekvence. (Předpokládané evoluční stáří). (Kliknutím na obrázek zobrazíte jeho větší verzi)
Velmi malá variabilita funkčních sekvencí UB je z evolučního hlediska problematická a byla ještě umocněna nálezem více rodin těchto proteinů (viz obr. 7).
Podle současných evolučních názorů žila první buňka eukaryot asi před 2,7 tisíci lety.36 Prokaryota nemají nic, co by se podobalo UB, a většina evolučních biologů se stále domnívá, že eukaryota vznikla z nich. Na základě rozlišovacích vzorců UB z mého souboru dat jsou si rostliny (SDA) a houby (SDS) podobnější než živočichové (PES). Použití jiných genů a předpoklad, že větší sekvenční rozdíl znamená větší časovou divergenci od společného předka, vede k opačnému závěru, že živočichové jsou příbuznější houbám (společný předek anima-houby: 1513 mil. let) než rostlinám (společný předek živočichů-rostliny: 1609 mil. let).36 Jinými slovy, před 1,609 tisíci miliony let již musely být přítomny UB. Člověk ještě potřebuje společného předka s verzí UB, kterou používají Cercozoa a Foraminifera, a pravděpodobně se tento první UB neobjevil okamžitě. To ilustruje horní část obr. 7, podle níž by před více než 1,61 tisíce milionů let teoretický společný předek po určitou dobu disponoval stejnou sekvencí. Protože evolucionisté neustále mění datum, které chtějí použít pro společného předka Cercozoa a Foraminifera, nemohu extrapolovat společného předka s linií živočichové-houby-rostliny. Podle analýzy založené na sekvencích malých podjednotek rDNA37 se Foraminifera údajně rozvětvily blízko základny eukaryotického stromu, stovky milionů let před rozdělením živočichů a rostlin. Všimněte si, že Foraminifera mají plně funkční UB. Pozdější autoři navrhovali méně starý původ.
Evoluční interpretace dat vede k závěru, že UB musel být přítomen u prvního eukaryota nebo se objevil krátce poté. Jinými slovy, čtyři linie zůstaly prakticky beze změny po dobu přibližně 1,5 tisíce milionů let. Na vytvoření úplně prvního funkčního UB a mnoha dalších nezbytných proteinů by však bylo k dispozici mnohem méně času.
V pozdějším článku představím sekvenční data dostupná pro UBL, která spolu s naší současnou analýzou UB činí evoluční interpretační rámec pro jejich náhodný vznik velmi problematickým.
Závěry
Vidíme, že místo 4 tisíc milionů let na vytvoření sekvence DNA kódující ubikvitin vyžaduje použití evolučního modelu vnitřně konzistentním způsobem, aby byl přítomen již v prvním eukaryotu nebo aby vznikl nerealisticky rychle poté. To se zdá být spíše zázrakem, vezmeme-li v úvahu složitost biochemických procesů, kterých se UB účastní, a potřebu současného výskytu enzymů E1, E2, E3, deubikvitinačního enzymu a proteazomu. Tyto enzymy jsou přesně přizpůsobeny složené struktuře UB, což se projevuje nesnášenlivostí UB vůči mutacím. Tyto enzymy nemají žádnou jinou známou funkci a neinteragují s UBL, domnělými prekurzory UB. Kromě toho by „pravidla Nend“,26 která určují poločas rozpadu proteinů, musela být koordinována napříč nepříbuznými proteiny pro dobro organismu jako celku. Dokud nebude degradace založená na UB zdokonalena, byla by velmi škodlivá.
Obrázek 8. Fylogenická evoluční očekávání za předpokladu nejjednodušší divergence diagnostického vzoru ubikvitinu pro živočišné, houbové a rostlinné formy života.
Obrázek 9. Fylogenní vztah mezi živočišnými, rostlinnými a houbovými formami života podle současné evoluční teorie založené na několika genech. Údaje z ref. 37. (Kliknutím na obrázek zobrazíte jeho větší verzi)
Vzhledem k velkému počtu klíčových regulačních procesů, kterých se UB účastní, je pro tento typ buněk nepostradatelný. Prokaryota mají nesouvisející schéma odbourávání regulačních proteinů.
Analýza dostupných údajů ukazuje, že existují nejméně čtyři rodiny ubikvitinu. Ze sekvenčních variací lze oprávněně usuzovat, že živočichové, houby a rostliny od počátku své existence vždy disponovaly příslušným schématem UB (obr. 7). Důkazy o sekvencích UB nepodporují tvrzení, že se oddělily od společného předka. Při analýze pomocí UB se houby-živočichové jeví jako méně podobné (PES-SDS) než houby-rostliny (SDS-SDA) (obr. 8), zatímco interpretace sekvenčních dat z jiných genů s evolučními brýlemi naznačuje opak (obr. 9).
Nepatrný rozsah sekvenční variability zjištěný v rámci jednotlivých rodin ubikvitinu naznačuje, že tvrzení o vzniku darwinistickými procesy je neopodstatněné. Šance na kódování minimálně první verze, na kterou by mohl působit přírodní výběr, cca 4X10-83, je nekonečně malá.
Možná, že ve skutečnosti existuje mnohem více přijatelných variant UB, než jsme odhadovali, a možná, že mutační rychlosti byly v minulosti mnohem vyšší, například 10-6 na pár bází. Je však zřejmé, že s těmito předpoklady stále neuděláme ani malý krok k překonání nepravděpodobnosti, že bychom byli schopni náhodně zakódovat původní UB. A to poukazuje na druhou potíž, s níž se evoluční teorie potýká: proč je tedy po více než tisíci milionech let mutací v několika nezávislých liniích tak malá variabilita? Během této doby by v průměru každý pár bází UB zmutoval více než 1041krát,38 čímž by se do dnešní doby vytvořily rozsáhlé polymorfismy a fixní alternativy.
V tabulce 27 je třeba zohlednit skutečné množství variability, přičemž je třeba mít na paměti, do které ze čtyř identifikovaných rodin UB organismus patří. Variabilitu v pozicích reziduí 19, 24 a 57 lze v podstatě ignorovat, protože klasifikují rodiny UB. Zbývající variabilitu lze v prvním přiblížení rozdělit do tří skupin (živočichové, houby a rostliny).
Evoluční teorie by naznačovala, že tyto linie zůstaly dramaticky neměnné v průměru po dobu asi 1,5 tisíce milionů let. Kreacionista by tvrdil, že data ukazují velmi malou variabilitu sekvencí a že ubikvitin se podílí na složitých procesech, které vyžadují přesné vyladění mnoha dalších proteinů současně, aby mohl fungovat – nádherný příklad neredukovatelné složitosti.
Dodatek 1
Výpočty pravděpodobnosti pomocí teorie informace
Předpokládejme, že náš soubor dat je reprezentativní pro míru variability, kterou funkční ubikvitin umožňuje. Níže použité výpočty podle Shannonovy informační teorie byly v tomto časopise již vysvětleny.9 Metoda snižuje počet možných náhodných polypeptidů o délce 76 aminokyselin a tvrdí, že mnohé z nich patří do množiny s velmi nízkou pravděpodobností.9 Tím se zvyšuje pravděpodobnost náhodného nalezení počátečního, který by pak mohl přírodní výběr doladit.
Definujte pj jako pravděpodobnost, že se na pozici zbytku „l“ v proteinu UB nachází přijatelná aminokyselina. Pomocí genetického kódu vážíme podle synonymních kódů Σpj přes všechny aminokyseliny tolerované na dané pozici rezidua. Pro každé místo vypočítáme:
Rovnice 1.
p1j = pj / Σpj
(1)
z níž se entropie na každém místě l vypočítá jako:
Rovnice 2.
H1 = Σjp‘jlog2p‘j
(2)
Pro můj soubor dat se vypočítá entropie 40,94 bitů pro 76 zbytků.
Použití aproximace pij na základě rozložení dvaceti přirozených aminokyselin vede k odhadu entropie DNA ve všech genomech9,17 ve výši 4,139 bitů na základě (3):
Rovnice 3.
H = – Σ20j=1pilog2pj
(3)
Pak se odhaduje, že efektivní celkový počet sekvencí DNA (s výjimkou sekvencí v souboru s nízkou pravděpodobností) je:
Rovnice 4.
2H = 2(76 X 4.139)
(4)
Efektivní počet funkčních sekvencí UB vypočítáme jako:
Rovnice 5.
2(40.94)
(5)
a podíl funkčních sekvencí UB ve srovnání s náhodnými polypeptidovými řetězci o délce 76 zbytků je poměr (5) / (4): 4.3X10-83.
Reference
- www.ncbi.nlm.nih.gov/BLAST/; použitý protein-proteinový nástroj BLAST (blastp).
- Bezplatný software ActivePerl si můžete stáhnout ze stránek: www.activestate.com/Products/Download/Download.plex?id=ActivePerl, 20 September 2005.
- https://dl0.creation.com/articles/p043/c04346/appendix_a_b_jun_28_2005.txt, (Appendix A a Appendix B).
- Bezplatný ClustalX software si můžete stáhnout ze stránek: www-igbmc.u-strasbg.fr/BioInfo/ClustalX/Top.html, 20 September 2005. Příklad vícenásobného zarovnání sekvencí s použitím některých ubiquitinových sekvencí.
- https://dl0.creation.com/articles/p043/c04346/ubfigure01small.png.
- Online data pro ubikvitinové sekvence jsou k dispozici na adrese: creation.com/images/journal_of_creation/vol19/ table_ubiqutin_full_set_june_25_2005.xls.
- Online tabulka s přehledem variability ubikvitinových sekvencí: creation.com/images/journal_of_creation/vol19/ubtableb.htm.
- Online tabulka Excelu se všemi variabilitami ubikvitinových sekvencí creation.com/images/journal_of_creation/vol19/ table_ubiquitin_variable_residues_june_25_2005.xls.
- Truman, R. and Heisig, M., Protein families: chance or design? TJ 15 (3):115–127, 2001.
- Počet alternativních aminokyselin přítomných na každé pozici rezidua v tabulce 3: 3x3x2x3x5x4x4x2x4x5x6x3x2x3x3 = 167961600, který předpokládá nezávislost na kontextu u údajů vykázaných k srpnu 2004. Všimněte si, že v tabulce 3 bylo skutečně identifikováno pouze 55 alternativ. Skutečný počet funkčních alternativ podle tabulky 3 je pravděpodobně mnohem nižší než přibližně 168 milionů. Například ze 158 organismů uvedených v souboru údajů je mnoho z nich identických. Vyčerpávající zkoumání funkčních alternativ ubikvitinu (ref. 1) během května 2005 pro stejný organismus ukázalo vždy méně než 10 dosud nahlášených alternativ, což znamená, že na základě stávajících údajů by bylo předpovězeno < 1582x10 variant, jak je uvedeno v tabulce 3. Předpoklad kontextové nezávislosti má dramatické důsledky, které se zvyšují s počtem pozic reziduí vykazujících variabilitu.
- Ref. 5, viz organismy s id 39 a id 123.
- Ref. 5, viz organismy s id 39, 152 a 153.
- Ref. 5, viz organismy s id 147 a id 148.
- Ref. 5, viz organismy s id 127 a id 130.
- Archibald, J.M., Longet, D., Pawlowski, J. and Keeling, P.J., A novel polyubiquitin structure in Cercozoa and Foraminifera: evidence for a new eukaryotic supergroup, Mol. Biol. Evol. 20 (1):62–66, 2003.
- Scherer, S. and Loewe, L., Evolution als Schöpfung? in: Weingartner, P. (Ed.), Ein Streitgespräch zwischen Philosophen, Theologen und Naturwissenschaftlern, Verlag W. Kohlhammer, Stuttgart; Berlin; Köln: Köhlhammer, pp. 160–186, 2001.
- Yockey, H.P., Information Theory and Molecular Biology, Cambridge University Press, Cambridge, p. 250, 1992.
- Fersht, A.R., DNA replication fidelity, Proceedings of the Royal Society ( London ) B 212 :351–379, 1981.
- Drake, J.W., Charlesworth, B., Charlesworth, D. and Crow, J.F., Rates of spontaneous mutation, Genetics 148 , 1667, 1998.
- Grosse, F., Krauss, G., Knill-Jones, J.W. and Fersht, A.R., Replication of fX174 DNA by calf thymus DNA polymerase a: measurement of error rates at the amber-16 codon, Advances in Experimental Medicine and Biology 179 :535–540, 1984.
- Spetner, L., Not by Chance! Shattering the Modern Theory of Evolution , The Judaica Press, Inc., Chapter 4, 1998.
- Wagner, A., Energy constraints on the evolution of gene expression, Mol. Biol. Evol. 22 (6):1365–1374, 2005.
- ReMine jako alternativní přístup k evolučním scénářům založený na omezeních objasnil Haldaneovo dilema. Reprodukční nadbytek je nutný k pokrytí všech způsobů, jak mohou organismy zahynout (cit.33 ), a pokud má zvýhodněný mutant převládnout nad původním typem, je zapotřebí více potomků. Počet potomků nutných pro přizpůsobení se evolučním scénářům se stává nerealisticky vysokým.
- Obecně platí, že v každé generaci zmutuje maximálně jedna nová aminokyselina. Přesná analýza by vyžadovala zohlednění kontextu reziduí. Vícenásobné změny vyvolávající kompenzační účinky nelze účinně testovat evolučními procesy, které obecně mění vždy jen jednu aminokyselinu. Jinými slovy, metodou pokusu a omylu lze testovat velmi omezenou podmnožinu možných řešení.
Předpokládejme, že je třeba změnit pět konkrétních aminokyselin, aby vznikl protein s novou funkcí. Z 20 možných aminokyselin na každé z pěti pozic je obecně přijatelných několik. Pravděpodobnost výskytu jediné mutace, která poskytne jednu z přijatelných aminokyselin, bude v průměru asi 10-10 na organismus. Tuto pravděpodobnost je třeba překonat pětkrát. Jaká je pravděpodobnost, že k takové přeměně dojde? Za předpokladu, že se do snahy zapojily všechny organismy, které kdy mohly žít, dostaneme pravděpodobnost 1046 x 10-50 = 0,0001.
Samozřejmě je pravděpodobné, že během této doby vzniknou i další nežádoucí mutace, které vytvoří další překážky. - Nepublikované výsledky, článek v přípravě.
- Glickman, M.H. and Ciechanover, A., The ubiquitin-proteasome proteolytic pathway: destruction for the sake of construction, Physiol Rev. 82 :373–428, 2002.
- Krebber, H., Wostmann, C. and Bakker-Grunwald, T., Evidence for the existence of a single ubiquitin gene in Giardia lambia , FEBS Letters 343 :234–236, 1994.
- Varshavsky, A., The N-end rule and regulation of apoptosis, Nature Cell Biology 5 :373–376, 2003.
- Hemelaar, J., Borodovsky, A., Kessler, B.M., Reverter, D., Cook, J., Kolli, N., Gan-Erdene, T., Wilkinson, K.D., Gill, G., Lima, C.D., Ploegh, H.L. and Ovaa H., Specific and covalent targeting of conjugating and deconjugating enzymes of ubiquitin-like proteins, Molecular and Cellular Biology 24 (1):84–95, 2004.
- Wilkinson, K.D., Ubiquitin-dependent signalling: the role of ubiquitination in the response of cells to their environment, J. Nutr. 129 :1933–1936, 1999.
- Hershko, A. and Ciechanover, A., The ubiquitin system, Annu. Rev. Biochem. 67 :425–479, 1998.
- Kuhn, T., The Structure of Scientific Revolutions, 2 nd ed. enl., Chicago University Press, Chicago, 1970. See also: Ratsch, D., The Philosophy of Science: The Natural Sciences in Chris tian Perspective, IVP, Downers Gr., IL, 1986.
- Scheven, J., Mega-Sukzessionen und Klima im Tertiär. Katastrophen zwischen Sintflut und Eiszeit, Hänssler, Neuhause-Stuttgart , Germany, 1988.
- Vardiman, L., Snelling, A.A. and Chaffin, E.F., Radioisotopes and the Age of the Earth, Institute for Creation Research, El Cajon , CA , 2000.
- news.nationalgeographic.com/news/2003/09/0908_030908_beegene.html, 19 September 2005. „Proč se z neoplozených včelích vajíček stávají samci, zatímco z oplozených vajíček se rodí samice dělnice nebo královny? Podle nového výzkumu spočívá odpověď v jedinečné formě genetické pohlavní determinace. Samičky včel nesou dvě mírně odlišné kopie genu pro určení pohlaví: jednu od matky a druhou od otce, které mohou společně působit na vývoj samiček. Neoplozená včelí vajíčka samců však mají pouze jednu kopii genu od matky, což způsobuje, že jejich vývoj probíhá samčí cestou. Jedná se o zcela odlišný genetický systém, než jaký byl objeven u jiných živočichů [například u lidí, myší a některých červů a much].“
- Hedges, S.B., Blair, J.E., Venturi, M.L. and Shoe, J.L, A molecular timescale of eukaryote evolution and the rise of complex multicellular life, BMC Evolutionary Biology 4 :1–9, 2004; www.biomedcentral.com/1471-2148/4/2#B1.
- Pawlowski, J., Bolivar, I. , Guiared-Maffia, J. and Gouy, M., Phylogenetic position of the Foraminifera inferred from LSU rRNA gene sequences, Mol. Biol. Evol. 11:929–938, 1994.
- (76 aminokyselin)(3 páry bází/aminokyselina)(10-6 mutací/pár bází x organismus)(0,25 x 1046 organismů) = 5,7 x 1041 mutací v průměru na každý pár bází UB.

{kind=link}